웹의 3대 기술 - URL, HTML, HTTP

월드 와이드 웹의 3대 요소
보통 인터넷과 동일시할 정도로 인터넷을 대표하는 서비스가 된 웹(WWW)은 1989년 팀 버너스 리가 아이디어를 제시하고, 동료들과 함께 개발하여 1990년 12월 25일 구현된 최초의 웹을 시작으로 발전한 것입니다.
팀 버너스 리가 웹을 개발하면서 정의한 세 가지 주요 기술은 HTML, URL, HTTP입니다.
서버 클라이언트 구조를 사용한 웹은 HTML이란 언어로 만든 웹 페이지를 웹 서버에 저장하고, 다수의 웹 클라이언트(웹 브라우저)가 웹 서버에게 웹 페이지를 보여 달라고 요청하는 단순한 시스템입니다. 팀 버너스 리는 웹 페이지가 어디에 저장되어 있는지를 URL로 표시하고, 웹 클라이언트와 웹 서버가 웹 페이지를 주고받는 방식을 HTTP라는 프로토콜로 정의했습니다.
웹을 설계하기 위해 사용한 서버 클라이언트 구조, HTML에 적용된 하이퍼텍스트와 마크업 언어, URL에 사용된 도메인, HTTP가 전송 프로토콜로 사용하는 TCP/IP는 이미 사용되고 있던 기술들이었습니다. 그래서 팀 버너스 리는 "나는 그저 하이퍼텍스트란 아이디어를 꺼내 그걸 전송 제어 프로토콜과 도메인 네임 시스템(DNS)에 연결했을 뿐이다."라고 말하곤 했습니다.
서버/클라이언트 구조 자세히 ⇒ 서버/클라이언트와 웹 서비스
문제를 풀기 위해 기존의 아이디어와 기술을 연결하다
당시 팀 버너스 리가 일하던 유럽입자물리연구소(CERN)에는 약 1만여 명의 연구원들이 각기 다른 대륙에 흩어져 일하고 있었습니다. 연구원마다 사용하는 컴퓨터의 하드웨어와 소프트웨어가 달라 서로 다른 매뉴얼로 문서를 작성하고 있었습니다. 연구원들이 작성한 문서도 체계적으로 관리되지 않고, 서로 공유되지 않아 원하는 정보를 찾기도 어려웠습니다. 팀 버너스 리는 어떻게 하면 전 세계에 흩어져 있는 연구원들이 연구 정보를 공유하고 연구원들이 원하는 정보를 빠르고 쉽게 찾아볼 수 있을까 하는 문제의식에서 출발하여 웹을 고안하였습니다.
팀 버너스 리가 말한 것처럼 그는 문제를 풀기 위해 기존의 아이디어와 기술들을 연결하였습니다. 그가 만든 새로운 시스템은 오래된 아이디어와 당대의 기술을 새롭게 연결하고 응용한 결과 탄생한 것입니다. 과거의 기술로는 구현할 수 없었던 아이디어가 그가 살던 시대의 기술로는 가능했습니다. 1969년 최초의 인터넷이 등장하고, 1975년 TCP/IP 프로토콜이 개발되었으며, 1984년 DNS 시스템이 만들어졌습니다. 이런 기술의 흐름을 이해하고 자신이 풀고자 하는 문제에 적용할 수 있었던 지식과 능력뿐만 아니라, 그는 누구든 쉽게 정보에 접근할 수 있어야 한다는 자신만의 확고한 철학을 갖고 있었습니다. 정보 공유에 대한 확고한 철학을 바탕으로 IT를 응용하여 문제를 푼 결과 탄생한 것이 웹(WWW)입니다.

웹의 주요 기술이 만들어지는 과정을 살펴보면서 테크 스타트업 창업자가 자신만의 철학 또는 비전을 갖고, IT를 응용하여 문제를 풀어가며 새로운 서비스를 만들어 내는 것이 어떤 의미인지 생각해보는 계기가 되었으면 하는 바람입니다.
초기 웹의 탄생과 응용 기술
서버 클라이언트 모델을 기반으로 정보 공유 시스템을 설계하다
팀 버너스 리는 인터넷에 연결된 컴퓨터를 통해 사람들이 정보를 공유할 수 있도록 서버 클라이언트 모델을 기반으로 정보 공유 시스템을 설계하였습니다. 하나의 서버에 다수의 클라이언트가 접속해서 서버가 제공하는 서비스를 이용하는 서버 클라이언트 모델을 응용해, 서버에 정보를 저장하고 그 서버에 저장된 정보를 여러 클라이언트가 열람하는 방법으로 어떻게 정보를 공유할 것인가 라는 문제를 풀기 시작한 것입니다.
당시 연구원들의 연구 진행과정이나 연구 성과를 공유하고자 했던 팀 버너스 리에게 정보는 곧 텍스트였습니다. 텍스트 정보를 서버에 저장하고 인터넷을 통해 클라이언트가 서버에 저장된 텍스트 정보를 열람하는 시스템을 구현하자는 아이디어가 웹의 출발점입니다.

세상의 모든 정보에 URL을 부여하다
팀 버너스 리는 유럽입자물리연구소(CERN)에서 사용하던 컴퓨터에 텍스트 정보를 저장하고 'CERN HTTPd'라고 이름 붙인 최초의 웹 서버를 만들었습니다. 이때 사용된 컴퓨터는 스티브 잡스가 애플에서 쫓겨난 이후 만든 넥스트(Next) 컴퓨터입니다.

텍스트 정보를 서버에 저장하면서 팀 버너스 리는 서버에 저장된 파일을 식별하기 위해 URI(Uniform Resource Identifier)를 도입했습니다. URI는 인터넷에서 정보와 정보를 구별하기 위해 통일된(Uniform) 형식으로 만든 정보 자원(Resource)의 식별자(Identifier)입니다.
URI 중에서 정보가 저장된 위치, 다시 말해 그 정보에 어떻게 접근(액세스, access)할 수 있는지를 알려주는 식별자를 URL(Uniform Resource Locator)이라고 합니다. URL은 정보의 위치로 정보를 식별하는 URI의 한 종류이자 하위 개념이지만, 웹에서는 URI와 URL을 사실상 동의어로 사용하고 있습니다.
World Wide Web, 즉 전 세계의 컴퓨터를 거미줄같이 연결한 가상의 공간을 만들어 정보를 공유하고자 했던 팀 버너스 리는 세상의 모든 정보에 URL을 붙여 전 세계에 흩어져 있는 컴퓨터에 저장된 파일을 식별하여 접근할 수 있는 시스템을 설계했습니다. 정보를 담은 텍스트 파일 등의 리소스에 URL을 붙여 웹 서버에 저장하고 URL을 공개함으로써, 누구나 URL로 웹 서버에 있는 리소스에 접근할 수 있게 한 것입니다.

URL은 다음 <그림 6>과 같이 크게 스킴, 도메인, 포트 번호와 파일 경로로 구성됩니다. 당시 인터넷에서 컴퓨터의 위치를 알려주는 역할을 하고 있던 도메인, 애플리케이션을 식별하기 위해 사용하고 있던 포트 번호, 컴퓨터 내에서 파일의 위치를 표시하던 디렉토리를 조합하여 인터넷 상에서 자원이 어디에 있는지를 알려주기 위한 주소 체계인 URL을 만들었습니다. 인터넷을 기반으로 한 정보 공유를 꿈꾸던 팀 버너스 리는 인터넷의 사실상의 표준으로 자리잡기 시작한 TCP/IP 프로토콜의 주소 체계를 응용하여 사용하기 쉽고 편리한 URL을 만든 것입니다.

하이퍼텍스트 개념을 응용하다
팀 버너스 리는 URL을 붙인 텍스트 정보를 서버에 저장하면서 어떻게 하면 사용자가 저장된 정보 중에서 원하는 정보를 좀 더 쉽게 빨리 찾을 수 있을까 하는 문제에 대해 고민합니다. 컴퓨터에 저장된 파일을 단순 검색하는 시스템보다 더 빠르게 원하는 텍스트를 찾을 수 있는 방법을 고민하던 그는 하이퍼텍스트 개념을 적용하여 문제를 해결합니다.
하이퍼텍스트(HyperText)는 테드 넬슨(Ted Nelson)이 1960년대 '3차원 이상의 공간, 초월'이라는 뜻의 '하이퍼(Hyper)'와 '문서'라는 뜻을 가진 '텍스트(Text)'를 합성해서 만든 단어입니다.
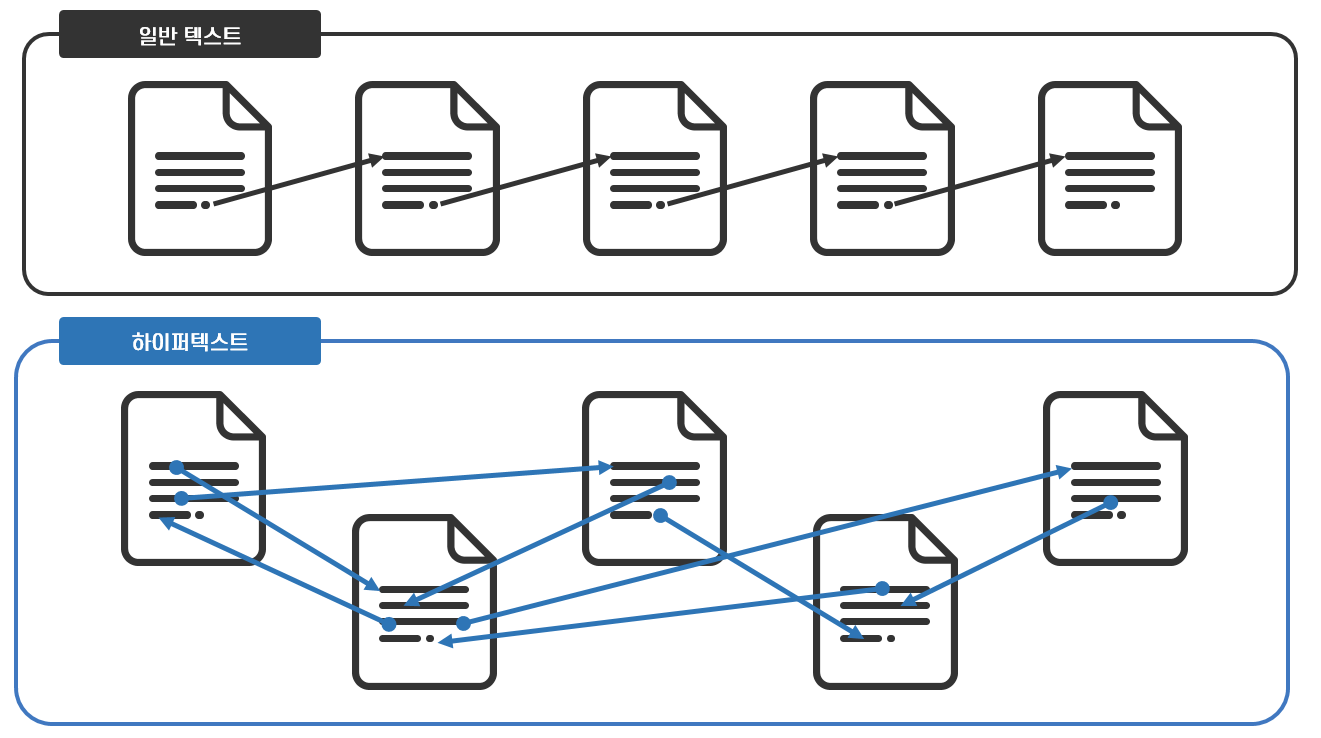
책 같은 일반 텍스트는 사용자의 필요나 사고의 흐름과 무관하게 좌에서 우로, 위에서 아래로, 정보를 순차적으로 담습니다. 사용자가 텍스트를 읽다가 모르는 단어나 궁금한 점이 생기더라도 그 텍스트는 사용자가 모르는 단어나 궁금한 점을 고려하지 않고 계속해서 정해진 정보를 전달합니다. 다시 말해 정보를 선형적, 고정적으로 전달하는 기존의 텍스트는 생각이나 연상에 의해 자연스럽게 흘러가는 사람의 사고 체계를 반영하지 못했습니다.
반면 하이퍼텍스트는 사용자가 생각하는 대로, 연상하는 순서에 따라 원하는 정보를 얻을 수 있게 하는 문서 체계를 의미합니다. 하이퍼텍스트는 선형적으로 연속된 정보를 제공하던 기존의 체계를 탈피하여 사용자가 원하는 정보를 원하는 때에 찾을 수 있는 비선형적이고 비연속적인 정보 체계를 꿈꾸며 만들어진 개념입니다.
하이퍼텍스트는 아래 <그림 7>과 같이 사고의 흐름대로 하나의 정보에서 다른 정보로 이동할 수 있다는 것을 표현한 추상적인 체계입니다. 이 추상적 체계는 하나의 정보를 노드(Node)라는 단위로 표시하고, 다른 정보로의 이동을 링크(Link)라고 표시하여, 상호 연결된 정보를 표현합니다. 따라서 하이퍼텍스트는 정보를 담은 노드들과 노드들을 연결시켜주는 링크들로 이루어진 정보의 집합, 다시 말해 노드들과 링크들로 이루어진 네트워크 구조를 가진 텍스트입니다.
네트워크의 노드와 링크 자세히 ⇒ <개발자의 단어> 노드, 호스트, 서버/클라이언트의 구분
하이퍼텍스트를 구현할 수 있는 HTML을 만들다
마크업 언어와 SGML
30년 동안 추상적인 아이디어로 존재하던 하이퍼텍스트를 구현하기 위해 팀 버너스 리는 SGML이라는 마크업 언어(Markup Language)를 응용합니다.
마크업 언어는 문서에 포함된 문장, 표, 그림 등과 같은 문서 내용에 대한 정보가 아니라, 그 문장과 표, 그림이 어떻게 배치되고, 글자는 어떤 크기와 모양을 가지며, 줄 간격과 여백은 어떠한지 등과 같은**, 문서 내용 이외에 추가되는 문서에 관한 정보를 표현하는 언어를 의미합니다.
보통 책을 읽으면서 공부할 때 중요한 내용을 구분하고 보기 쉽게 만들기 위해 중요한 단어에 동그라미를 그리기도 하고 중요한 문장에 위해 밑줄을 긋거나, 형광펜으로 칠하기도 합니다. 부족한 설명을 가필해서 넣기도 하고, 포스트잇을 붙이기도 합니다. 책의 내용을 건드리지 않으면서 책이 주는 정보를 보기 쉽게 구조화하는 이런 작업을 마크업*이라고 합니다.
*. 원래 마크업은 출판 인쇄 분야에서 원고를 교정할 때 원래 텍스트와는 별개로 편집자가 원고에 교정부호 등을 표시하는 것이었습니다. 그 용도가 점차 확장되어 문서의 구조를 표현하는 역할을 하게 되었고, 컴퓨터로 작성하는 전자 문서에서 문서의 구조를 표현하기 위한 체계로 확장된 것이 마크업 언어입니다.
컴퓨터를 이용한 전자 문서로 처리하는 데이터가 증가하면서 마크업을 사용해 데이터 내용 자체는 변경하지 않으면서 데이터의 가독성을 높이고 컴퓨터가 처리하기 쉽도록 전자 문서를 구조화하기 위해 만든 것이 마크업 언어입니다. 즉, 마크업 언어는 문서가 컴퓨터 화면에 표시되는 형식이나 데이터의 논리적인 구조를 명시하기 위한 규칙들을 정의한 언어입니다.
최초의 컴퓨터 마크업 언어는 1964년 개발되었고, 팀 버너스 리가 웹을 고안할 당시에는 SGML(Standard Generalized Markup Language)이라는 마크업 언어가 있었습니다. SGML은 1986년 국제표준화기구인 IOS가 전자문서의 표준 마크업 언어로 채택한 언어입니다. SGML은 기기나 시스템에 독립적인 범용성을 갖고 있어 확장이 가능하며 다양하게 응용할 수 있었습니다. 하지만 기능이 복잡해 SGML을 지원하는 소프트웨어를 개발하기가 쉽지 않은 단점이 있었습니다.
팀 버너스 리는 SGML을 응용하여 단순하고 사용하기 쉬운 마크업 언어인 HTML(HyperText Markup Language)을 개발했습니다.
HTML
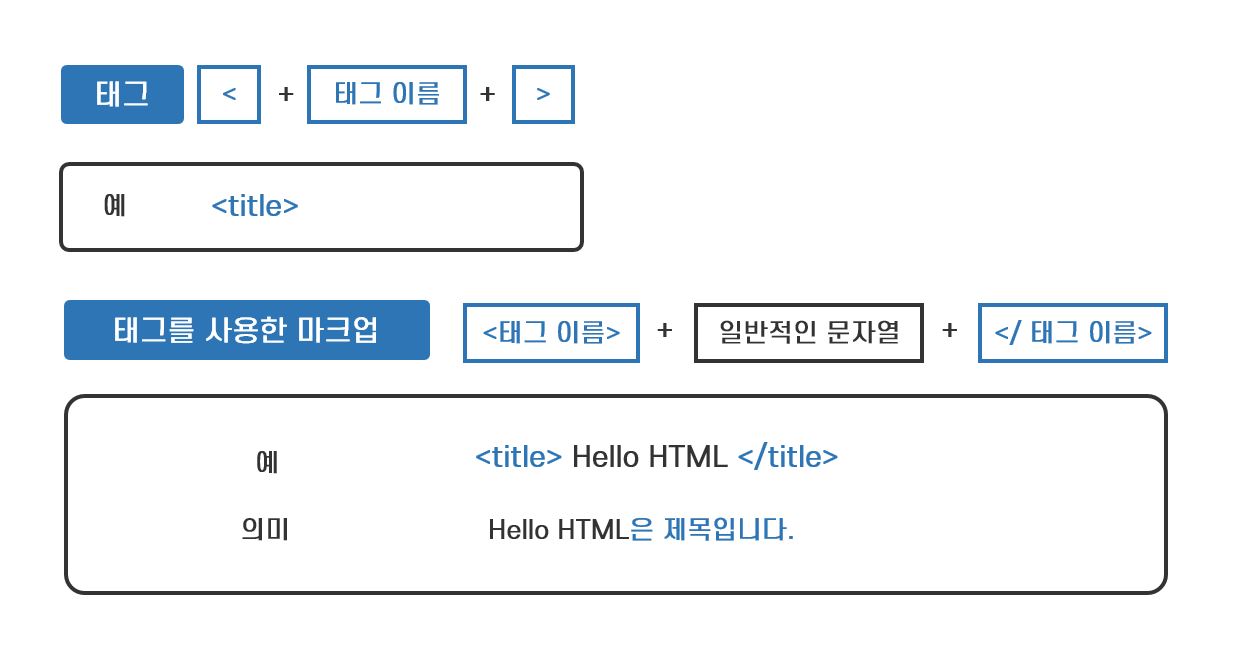
HTML은 태그(Tag)라는 기호를 사용해 텍스트의 특징과 의미를 마크업 하는 방식의 언어입니다. 태그는 <title>과 같이 꺽쇠 괄호인 '<>'로 둘러싸인 태그 이름(Tag Name)을 의미합니다. 텍스트 내용에 해당하는 일반적인 문자열과 태그에 사용되는 문자열을 구분하기 위해 '<>' 기호를 사용한 것입니다. <title>이라는 태그로 마크업 된 일반적인 문자열은 이 문자열이 제목이라는 의미를 담고 있습니다. title과 같은 태그 이름과 의미는 HTML 사양*에 정의되어 있습니다.
*. 팀 버너스 리가 최초로 마든 HTML 사양은 현재 팀 버너스 리가 만든 웹 표준화 단체인 W3C에서 관리하고 있습니다. 가장 최신 버전의 HTML 사양은 HTML 5입니다.
태그를 사용해 마크업을 할 때는 일반적으로 마크업을 할 문자열의 앞에 <태그 이름>을 문자열의 뒤에 </ 태그 이름> 붙입니다. <태그 이름>을 시작 태그(Start Tag), </태그 이름>을 종료 태그(End Tag)라고 합니다. 한마디로 일반적인 문자열을 시작 태그와 종료 태그로 감싸는 것이 마크업입니다.
HTML 해석기 웹 브라우저
문서 작성자는 텍스트를 작성하면서 문자열에 마크업을 해 문자열의 성격과 의미를 분명히 할 수 있습니다. 하지만 사용자 입장에선 마크업 된 텍스트, 즉 태그가 함께 삽입된 문서를 읽는다면 일반 텍스트만 작성된 문서를 읽는 것보다 복잡하고 이해하기 어렵습니다. 따라서 사용자에게 보여지는 문서는 태그의 의미를 시각적으로 반영하여 표현합니다.
예를 들어 아래 <그림 9>에서 h1 태그는 가장 중요한 제목이라는 의미를 갖고 있습니다. 가장 중요한 제목임을 나타내기 위해 다른 텍스트보다 크고 굵게 표현합니다. 중요한 내용을 의미하는 strong 태그는 굵은 글씨로, 단락을 의미하는 p태그는 다음 단락과 구분하기 위해 다음 텍스트가 오기 전에 공백 한 줄을 추가합니다.
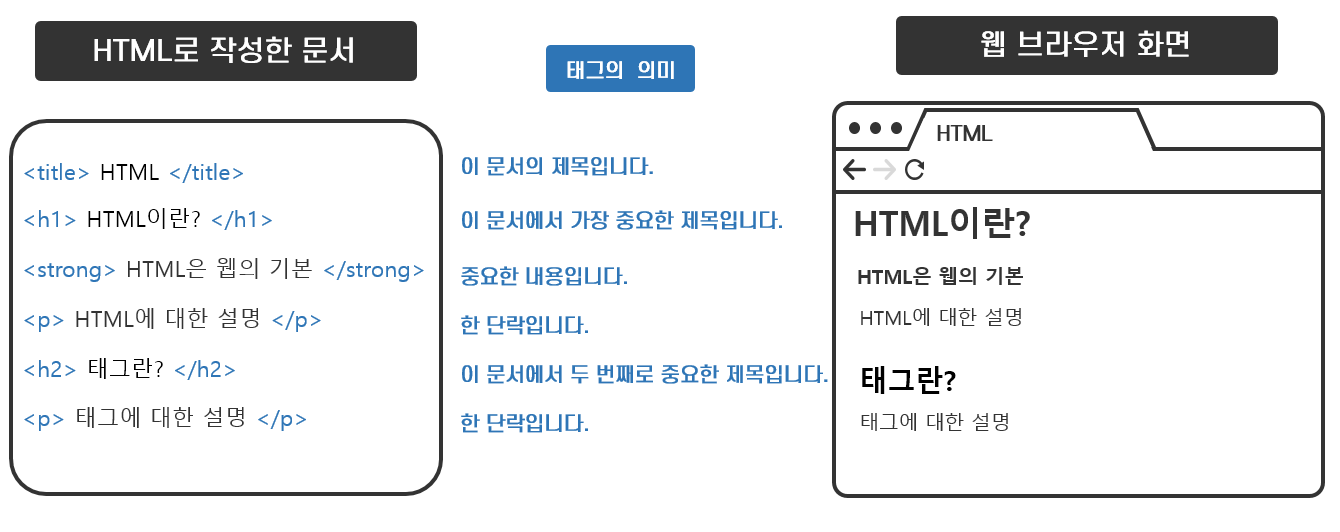
이렇게 HTML 태그의 의미를 해석하고 시각적으로 표현하여 사용자가 읽기 쉬운 문서로 출력해주는 애플리케이션이 웹 브라우저입니다. 즉, 웹 브라우저는 HTML로 작성한 문서(파일의 확장자가 html인 파일)를 해석하여 사용자가 읽기 쉬운 형태의 웹 페이지*를 보여주는 기능을 합니다.
*. 보통 웹 페이지와 HTML로 작성한 문서를 동의어 같이 사용하지만 엄밀히 구분하면, 웹 페이지는 HTML로 작성한 문서를 웹 브라우저가 해석해서 화면에 표시한 것입니다. HTML로 작성한 문서를 웹 브라우저가 해석하기 이전의 원본 데이터라는 의미에서 소스 파일(Source file)이라고 부르기도 합니다. 참고로 웹 페이지들이 하이퍼링크로 연결된 하나의 집합을 웹 사이트(Web site)라고 하며, 웹 사이트의 시작 페이지를 홈페이지(Home page)라고 합니다.
팀 버너스 리가 만든 최초의 웹 브라우저의 이름이 월드와이드웹(WorldWideWeb)이었습니다. 웹 서비스를 의미하는 World Wide Web과 띄어쓰기 여부로 구분했으나 헷갈린다는 지적에 따라 웹 브라우저 이름을 넥서스(Nexus)로 바꿨습니다.

HTML과 하이퍼텍스트 구현
텍스트 정보를 하이퍼텍스트로 만들기 위해 팀 버너스 리는 하이퍼링크 기능을 담은 a 태그를 만들었습니다.
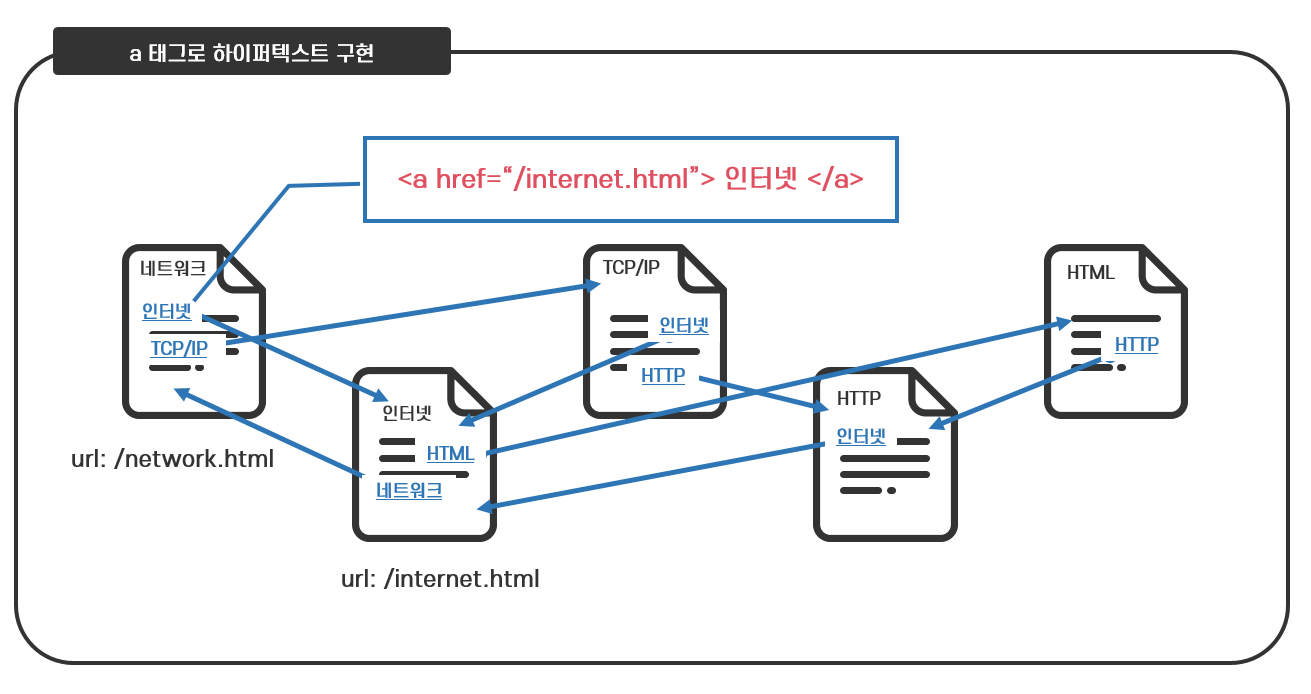
웹 페이지를 읽다 밑줄이 쳐진 파란색 단어나 문구를 클릭하면 새로운 웹 페이지가 열립니다. 이렇게 하나의 웹 페이지에서 다른 웹페이지로 연결되는 부분을 하이퍼링크(Hyperlink)라고 하며, 하이퍼링크를 구현하는 것이 HTML의 a 태그입니다.
다음 <그림 11>과 같이 시작 태그 안에 href(hypertext reference) 속성을 사용하여 연결할 페이지의 URL을 삽입합니다. 이러한 a태그로 마크업 된 문자열을 클릭하면 삽입된 URL로 바로 연결됩니다. a 태그로 마크업된 문자열은 보통 웹 브라우저가 밑줄이 그어진 파란 글씨로 출력합니다.

특정한 정보를 담은 HTML 문서를 만들어 웹 서버에 저장하고, 이 HTML 문서가 저장된 위치를 URL로 지정하여, 이 문서와 관련 있는 다른 HTML 문서의 문자열에 URL을 삽입한 a 태그로 마크업함으로써 특정 정보가 다른 정보와 연결되는 하이퍼텍스트가 구현되는 것입니다.
HTTP 프로토콜을 만들다
팀 버너스 리가 개발한 웹 브라우저는 HTML 파일을 해석하여 사용자가 읽기 쉬운 웹 페이지를 보여줍니다. 웹 페이지를 보는 사용자는 HTML의 a 태그로 마크업 된 문자열을 클릭함으로써 찾고자 하는 정보를 쉽게 찾을 수 있게 되었습니다.
이제 남은 것은 웹 브라우저가 설치되어 있는 컴퓨터(웹 클라이언트)가 웹 서버에 저장되어 있는 HTML 파일을 어떻게 가져올 것인가 하는 문제입니다. 즉, 웹 서버에 저장된 HTML 파일 중에서 웹 클라이언트가 원하는 파일을 어떻게 지정하고, 어떻게 받아올 것인지를 해결해야 하는 것입니다.
웹 서버와 웹 클라이언트가 파일을 주고받기 위해서, 다시 말해 두 컴퓨터가 통신을 하기 위해서 팀 버너스 리는 당시 인터넷에서 사용되고 있던 TCP/IP 프로토콜을 활용합니다.
TCP/IP 프로토콜의 적용
1968년 탄생한 인터넷은 1982년 TCP/IP 프로토콜을 표준으로 채택하여 정부와 대학, 연구기관의 네트워크로 사용되고 있었습니다. TCP/IP 프로토콜은 한 컴퓨터의 애플리케이션에서 다른 컴퓨터의 애플리케이션까지 데이터 전송을 책임집니다. IP 프로토콜은 인터넷에 연결된 모든 컴퓨터에 IP 주소(도메인)를 할당하여 컴퓨터 간에 데이터를 전송합니다. TCP 프로토콜은 컴퓨터 내의 애플리케이션에 포트 번호를 할당하여 애플리케이션에 데이터를 배분합니다.
따라서 TCP/IP 프로토콜을 기반으로 통신을 하면 한 컴퓨터의 애플리케이션에서 다른 컴퓨터의 애플리케이션까지의 데이터 전송은 TCP/IP 프로토콜에 맡기고, 애플리케이션끼리 어떤 데이터를 어떤 방식으로 주고받을지만 결정하면 됩니다.
TCP/IP 프로토콜 자세히 ⇒ 인터넷의 핵심인 TCP/IP
HTTP 프로토콜 개발
팀 버너스 리는 TCP/IP 프로토콜을 기반으로 하여 정보를 주고받을 수 있는 애플리케이션, 즉 웹 클라이언트에 설치할 애플리케이션과 웹 서버에 설치할 애플리케이션을 만들고 두 애플리케이션 간에 주고받을 데이터의 형식과 방법을 정하여 HTTP 프로토콜이라 이름 붙였습니다.
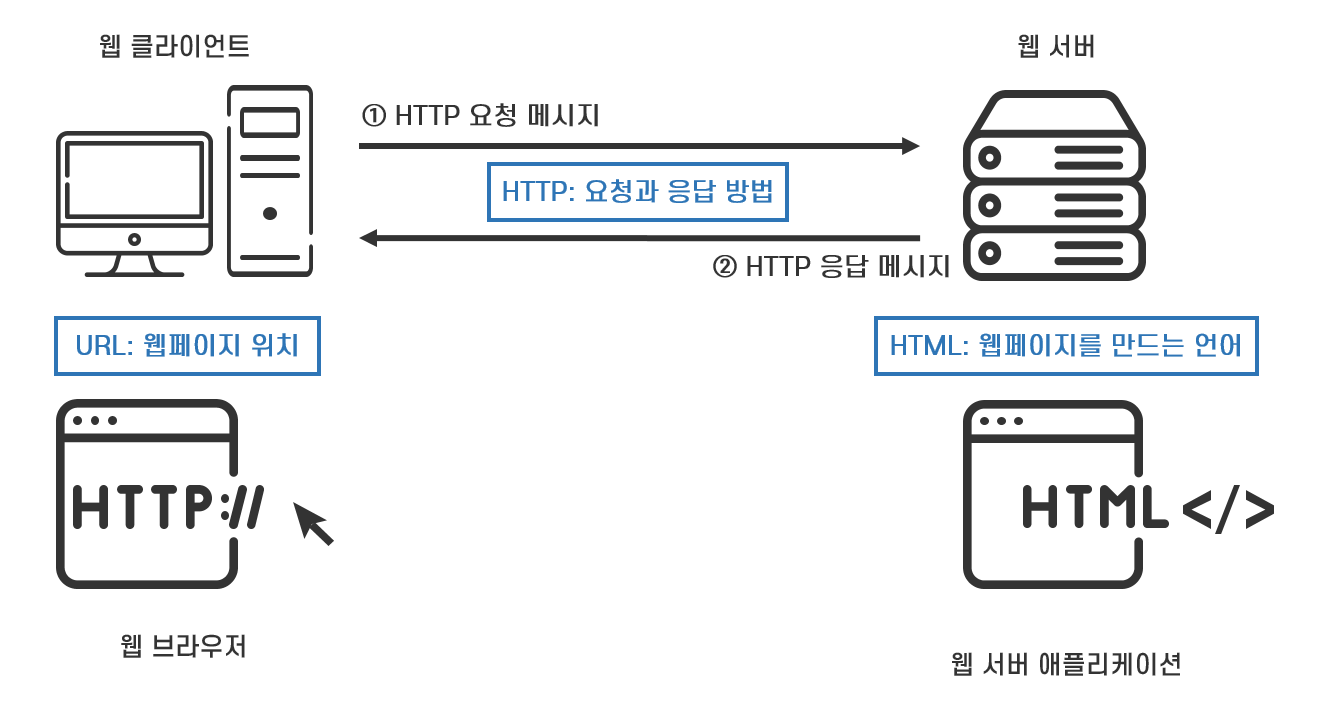
HTTP 프로토콜로 주고받을 데이터의 형식은 메시지입니다. 웹 클라이언트 애플리케이션은 웹 서버가 갖고 있는 HTML 파일 중에서 보고 싶은 파일을 보내 달라고 요청하는 메시지를 보냅니다. 웹 서버 애플리케이션은 웹 클라이언트 애플리케이션의 요청에 응답하여 보내 달라고 요청한 파일을 메시지에 담아 보냅니다. 이렇게 HTTP 프로토콜은 웹 클라이언트 애플리케이션이 요청 메시지(Request Message)를 보내고 웹 서버 애플리케이션은 응답 메시지(Response Message)를 보내는 단순한 방법으로 통신합니다.
팀 버너스 리가 만든 HTTP 요청 메시지는 "GET /index.html*"과 같이 GET(보내 달라)과 URL(웹 서버가 갖고 있는 파일)로 표현됩니다. 웹 서버가 갖고 있는 HTML 파일에 붙여진 URL을 통해 사용자(Client)는 열람하고자 하는 파일을 보내달라는 요청을 하는 것입니다.
*. 예시로 사용된 URL은 상대 URL입니다.
요청 메시지를 받은 웹 서버 애플리케이션은 웹 클라이언트 애플리케이션에게 요청받은 파일을 보내줍니다. 웹 서버 애플리케이션이 웹 클라이언트 애플리케이션에게 요청받은 파일을 보내 주는 것을 응답 메시지라고 합니다.

HTTP 통신을 하기 위해 요청 메시지를 보내고 응답 메시지를 받는 기능을 담아 코딩한 소프트웨어가 웹 클라이언트 애플리케이션인 웹 브라우저, 응답 메시지를 보내고 요청 메시지를 받는 기능을 담아 코딩한 소프트웨어가 웹 서버 애플리케이션이고 팀 버너스 리가 직접 코딩해서 만들었습니다.
웹 브라우저의 기능
웹 서버가 제공하는 정보를 이용하고 싶은 사용자는 웹 브라우저에 웹 서버가 공개한 URL을 입력하여 웹 서버가 제공하는 정보에 접근합니다.
웹 브라우저는 사용자가 입력한 URL을 해석하여 사용자가 원하는 정보의 리소스인 HTML 파일의 위치가 어디 있는지 확인하고 HTTP 요청 메시지를 작성해 웹 서버 애플리케이션에게 보냅니다.
웹 서버 애플리케이션이 요청한 HTML 파일을 담은 HTTP 응답 메시지를 웹 브라우저에게 보내면, 웹 브라우저는 웹 서버 애플리케이션이 보낸 HTML 파일을 읽고 해석하여 화면에 출력합니다.

이처럼 URL을 해석하고, HTTP 통신을 하고, HTML 파일을 해석하여 출력하는 웹 브라우저는 팀 버너스 리가 만든 웹의 3대 기술이 구현된 애플리케이션입니다. 웹 브라우저라는 애플리케이션 덕분에 사용자는 URL을 입력하는 단순한 방법으로 세상 어딘가에 존재하는 정보에 접근할 수 있게 된 것입니다.
팀 버너스 리가 URL을 만들기 전에는 인터넷에 산재해 있는 정보에 접근하기 위해 애플리케이션마다 다르고 복잡한 방식을 사용하고 있었습니다. URL이 쉽고 편리하게 정보에 접근할 수 있는 방법을 제공하자 다른 서비스를 제공하는 애플리케이션도 URL을 사용하기 시작했습니다. 웹을 위해 만들어진 URL이 FTP, 이메일 등 인터넷에 존재하는 다른 서비스도 지원하는 보편적인 규격으로 확장된 것입니다. 더불어 URL을 해석하는 애플리케이션인 웹 브라우저가 웹 서버뿐만 아니라 FTP 서버, 이메일 서버 등과 통신하는 범용적인 애플리케이션으로 사용되기 시작했습니다.
참고 자료
데이빗 고울리 외 4인, 이응준 외 1인 역, 「HTTP 완벽 가이드」, 인사이트, 2014.
배리 폴라드, 임혜연 역, 「HTTP/2 in Action」, 에이콘 출판, 2020.
시부카와 요시키, 김성훈 역, 「리얼월드 HTTP」, 한빛미디어, 2019.
우에노 센, 이병억 역, 「그림으로 배우는 HTTP & Network Basic」, 영진닷컴, 2015.
Gene, 김성훈 역, 「그림으로 배우는 네트워크 원리」, 영진 닷컴, 2020.
김종훈, 「소프트웨어 세상을 여는 컴퓨터 과학」, 한빛아카데미, 2018.
Ryuji Kitami, 이영란 역, 「그림 한 장으로 보는 최신 네트워크 용어 해설」, 정보문화사, 2016.
짐 볼턴, 홍석윤 역, 「웹을 뒤바꾼 아이디어 100」, 시드포스트, 2017.
'냐옹아 멍멍해봐(How to Speak IT) > 테크(IT) 문법' 카테고리의 다른 글
| 쉽게 이해하는 네트워크 20. HTTP 프로토콜 - 메서드와 상태 코드 (3) | 2020.12.04 |
|---|---|
| 쉽게 이해하는 네트워크 18. TCP/IP 응용(애플리케이션) 계층과 URL 구성 요소 및 종류 (2) | 2020.12.01 |
| 쉽게 이해하는 네트워크 17. TCP 프로토콜의 기능 및 특징 - 패킷 분할과 연결형 통신 (1) | 2020.11.29 |
| 쉽게 이해하는 네트워크 16. TCP/IP 전송 계층(트랜스포트 계층)과 포트(Port) 번호 (3) | 2020.11.24 |
| 쉽게 이해하는 네트워크 15. 도메인 의미와 계층 구조 및 DNS 네임 서버(ft. 도메인의 가치) (2) | 2020.11.20 |



